Graph Traversal
As a developer, you must understand what an execution plan is, how to interpret it, and most importantly, how to make it performant. To understand the execution plan, you must understand how a query starts and then how it is processed as the nodes are traversed in the graph.
Anchor of a query
When the execution plan is created, it determines the set of nodes that will be the starting points for the query.
The anchor for a query is often based upon a MATCH clause.
The anchor is typically determined by meta-data that is stored in the graph or a filter that is provided inline or in a WHERE clause.
The anchor for a query will be based upon the fewest number of nodes that need to be retrieved into memory.
Next, we will look at some examples of how queries are anchored based upon the hueristics used by the graph engine.
PROFILE MATCH (p:Person)-[:ACTED_IN]->(m)
RETURN p.name, m.title LIMIT 100In the above query, the Person nodes are the anchor for the query. This is because there are a total of 28,863 nodes in the graph which is what m represents. There are only 19,047 Person nodes so the execution will retrieve fewer nodes if it anchors with the Person nodes.
PROFILE MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
RETURN p.name, m.title LIMIT 100In the above query the Movie nodes will be the anchor for the query because there are fewer Movie nodes (9,125) than Person nodes (19,047).
PROFILE MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = 'Eminem'
RETURN p.name, m.titleIn the above query, a filter is specified which reduces the number of nodes that will be retrieved for the Person node. Satisfying the filter is the anchor for the query. If the Person nodes has an index on name, it only retrieves one record. If there is no index, it needs to scan/filter all Person nodes for the name property.
Multiple anchors
By default, an anchor set of nodes is determined by the metadata related to the query path and WHERE clauses to filter the query.
In some cases you may have more than one set of anchor nodes.
PROFILE
MATCH (p1:Person)-[:ACTED_IN]->(m1)
MATCH (m2)<-[:ACTED_IN]-(p2:Person)
WHERE p1.name = 'Tom Hanks'
AND p2.name = 'Meg Ryan'
AND m1 = m2
RETURN m1.titleIn this query, all p1 nodes are retrieved as well as all p2 nodes. This query has two sets of anchor nodes. It retrieves the anchor nodes before the equality filter is applied. The query planner tries to apply filters as early as possible to reduce cardinality (number of rows).
Expand to follow paths
After the anchor nodes have been retrieved, the next step if the query specifies a path is to follow the path. The loaded, initial nodes that are part of the anchor set have pointers to relationships that point to nodes on the other end of the relationships.
The goal here is to eliminate paths from the nodes in memory to nodes that will need to be retrieved. This is where specificity in the relationship types is important in your data model.
PROFILE MATCH (m:Movie)<--(p:Person)
WHERE p.name = 'Clint Eastwood'
RETURN m.titleThis query expands to 70 rows because Clint Eastwood has 70 relationships to movies.
PROFILE MATCH (m:Movie)<-[:DIRECTED]-(p:Person)
WHERE p.name = 'Clint Eastwood'
RETURN m.titleThis query expands to fewer rows because Clint Eastwood has fewer DIRECTED relationships to movies.
In addition, the expansion may lead to the need to inspect properties of the relationship and/or the properties of the Movie node. This inspection means that the nodes are brought into memory and possibly eliminated from the nodes in memory after they have been retrieved.
Cypher queries with multiple MATCH statements may execute differently than what you may expect.
You should always profile your queries to understand how the graph is traversed.
Basic query traversal
Now let’s learn a little more about how traversal works in Neo4j.
With this query:
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = 'Eminem'
RETURN m.title AS moviesHere is what happens when this query executes:
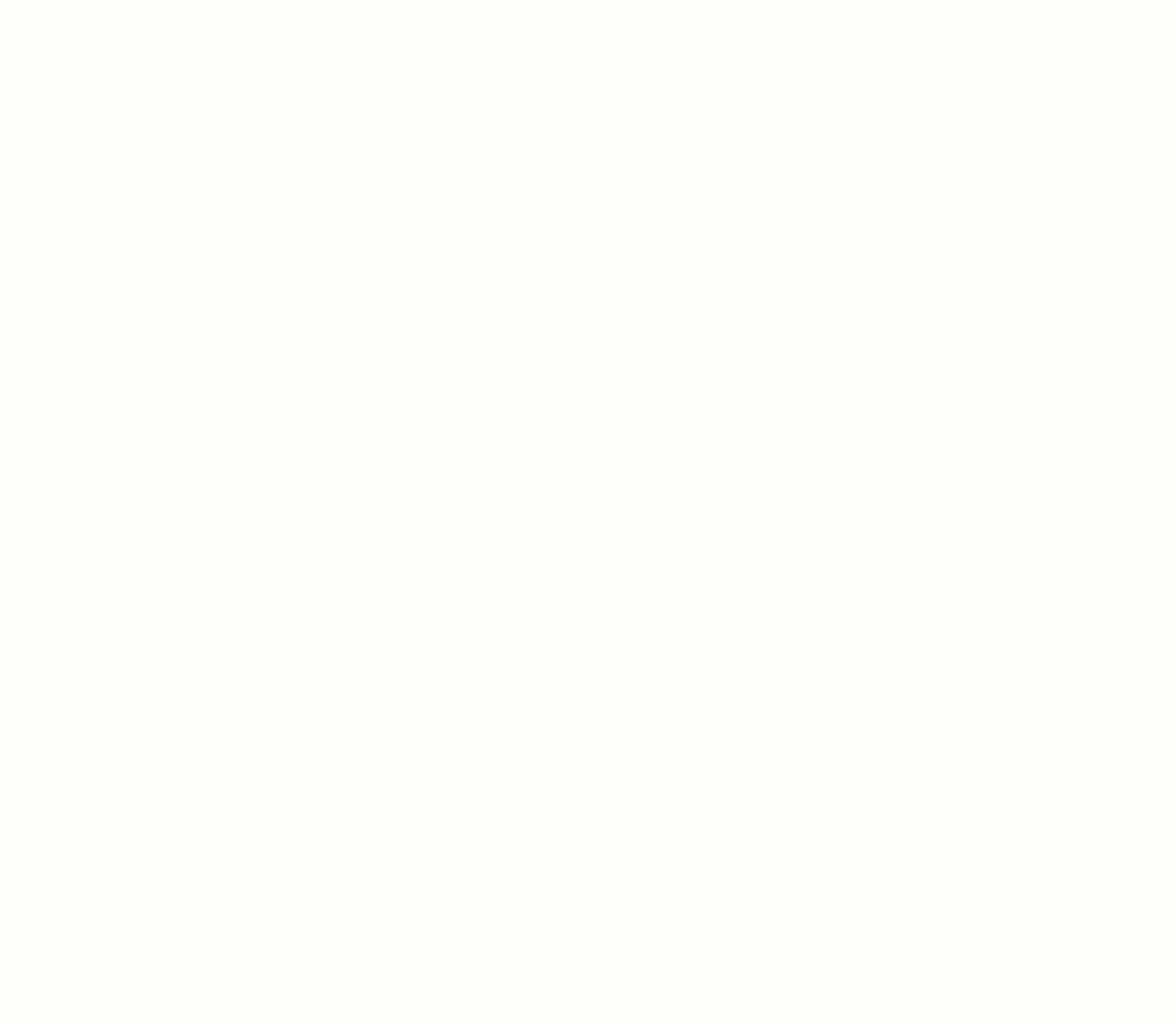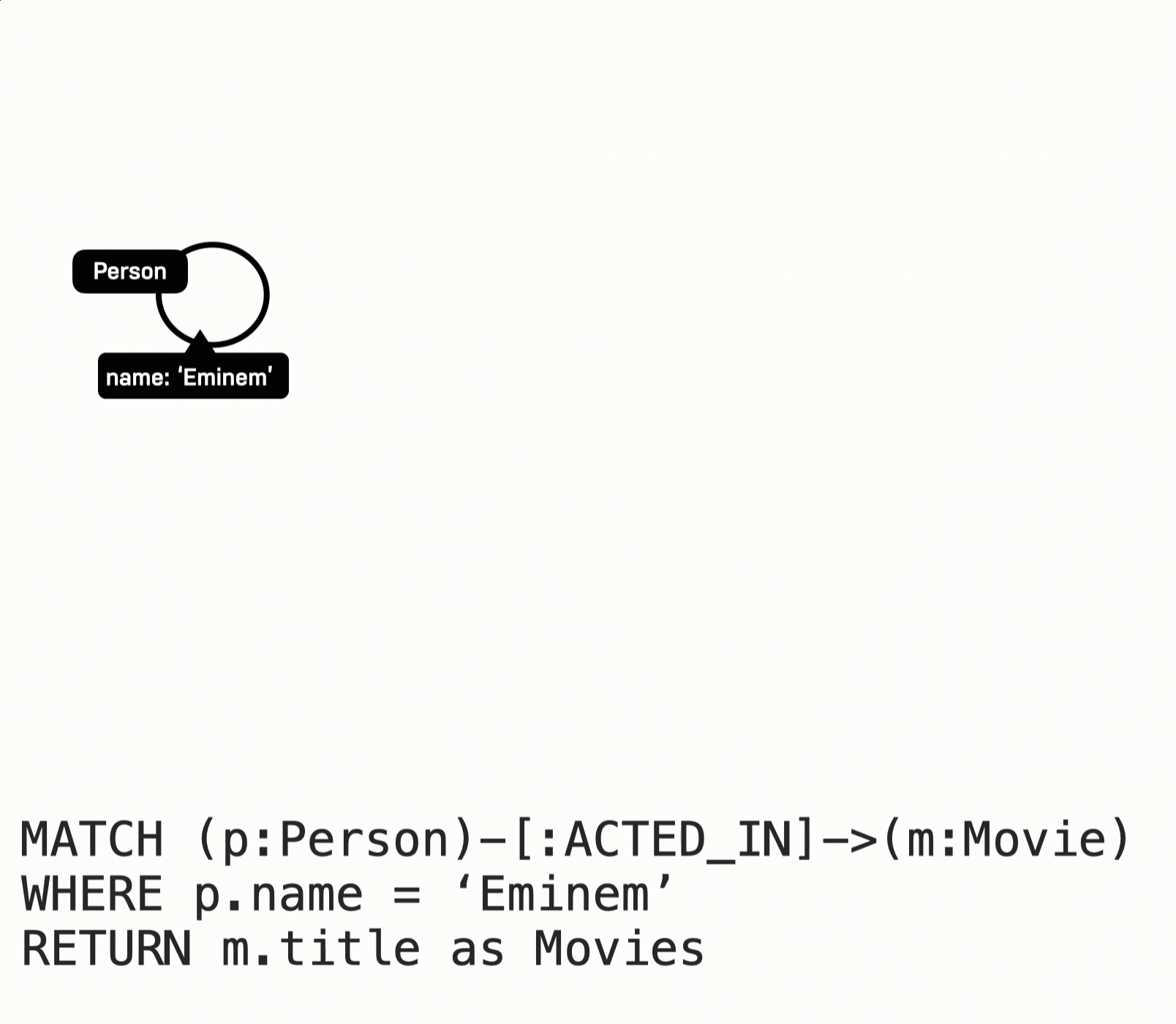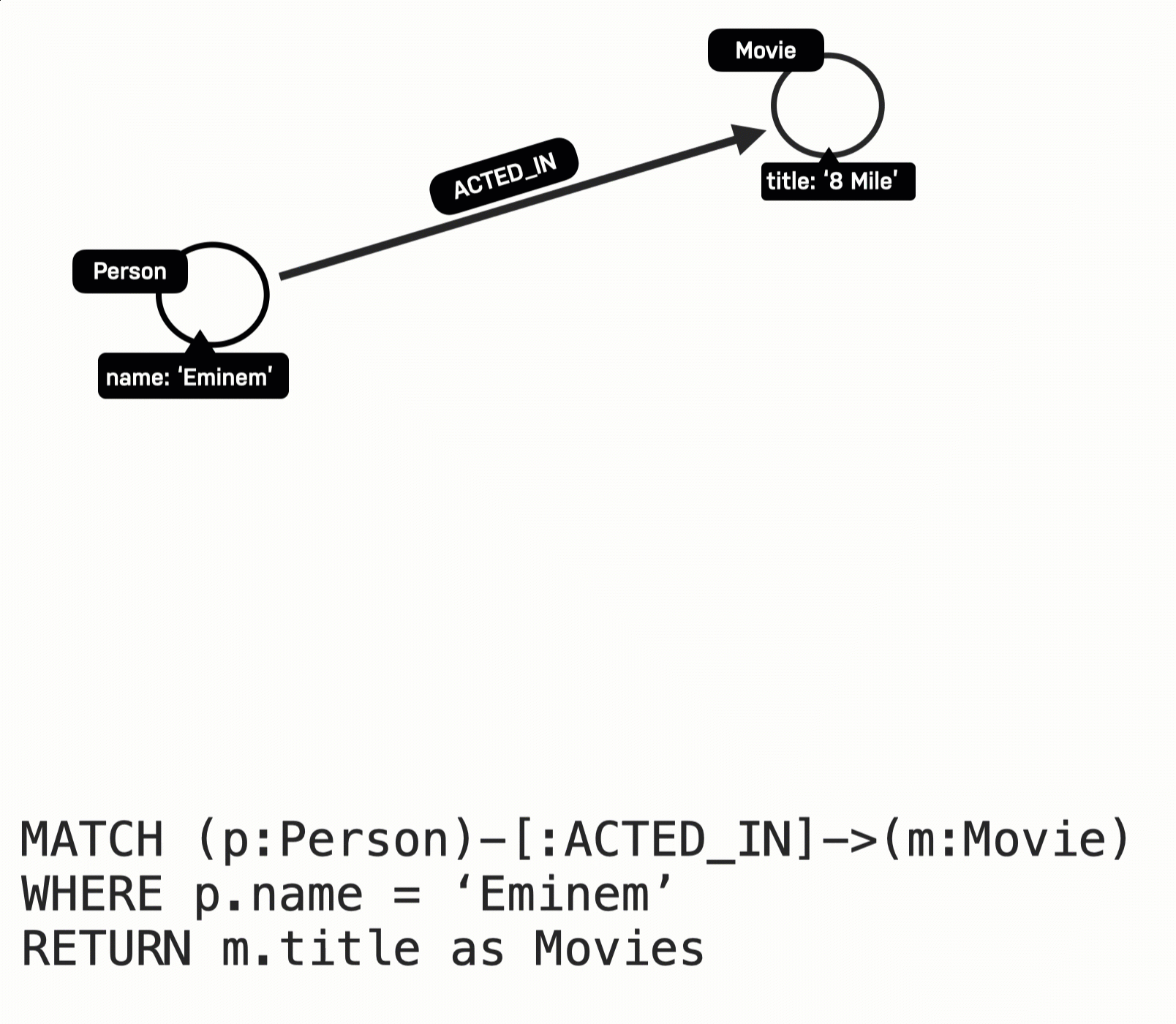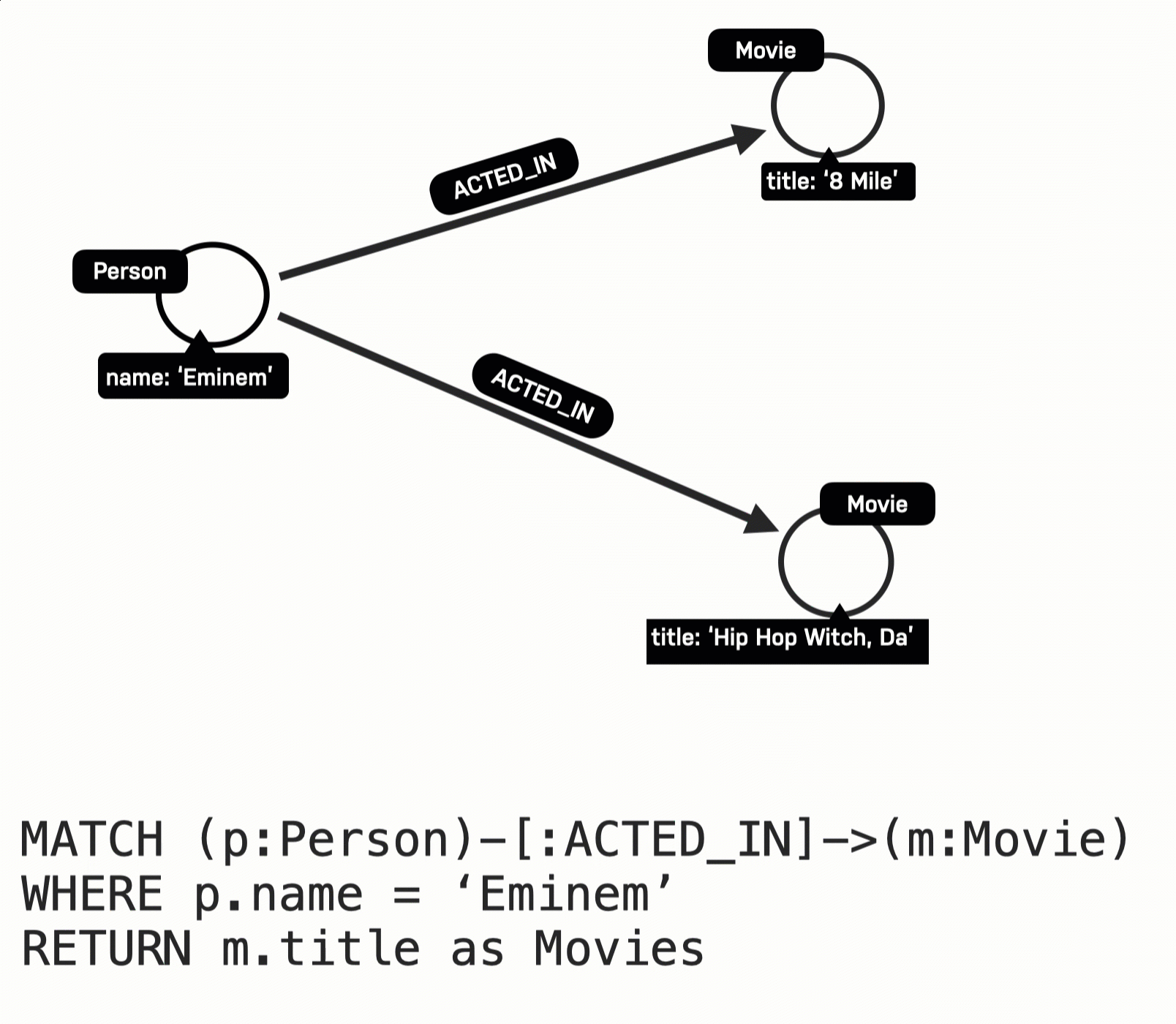
-
The Eminem Person node is retrieved.
-
Then the first ACTED_IN relationship is traversed to retrieve the Movie node for 8 Mile.
-
Then the second ACTED_IN relationship is traversed to retrieve the Movie node for Hip Hop Witch, Da.
-
The title property is retrieved so that the results can be returned.
Query traversal using multiple patterns
Here is another query that contains two patterns:
MATCH (p:Person)-[:ACTED_IN]->(m:Movie),
(coActors:Person)-[:ACTED_IN]->(m)
WHERE p.name = 'Eminem'
RETURN m.title AS movie ,collect(coActors.name) AS coActorsHere is what happens when this query executes:

-
For the first pattern in the query, the Eminem Person node is retrieved.
-
Then the first ACTED_IN relationship is traversed to retrieve the Movie node for 8 Mile.
-
The second pattern in the query is then used.
-
Each ACTED_IN relationship to the same 8 Mile movie is traversed to retrieve three co-actors.
-
If the ACTED_IN relationship has been traversed already, it is not traversed again.
-
Then the second ACTED_IN relationship is traversed to retrieve the Movie node for Hip Hop Witch, Da.
-
Each ACTED_IN relationship to the same Hip Hop Witch, Da movie is traversed to retrieve three co-actors.
-
The title property for the Movie node is retrieved so that the results can be returned.
Notice that for this query, a depth-first traversal occurs.
Query traversal using multiple MATCH clauses
Here is another query that contains two MATCH clauses:
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = 'Eminem'
MATCH (allActors:Person)-[:ACTED_IN]->(m)
RETURN m.title AS movie, collect(allActors.name) AS allActorsHere is what happens when this query executes:

-
For the first
MATCHclause in the query, the Eminem Person node is retrieved. -
Then the first ACTED_IN relationship is traversed to retrieve the Movie node for 8 Mile.
-
The second
MATCHclause in the query is then executed. -
Each ACTED_IN relationship to the same 8 Mile movie is traversed to retrieve all actors, including the relationship to the Eminem node.
-
Then the query returns back to the first
MATCHclause to traverse the ACTED_IN relationship to the Hip Hop Witch, Da movie. -
The second
MATCHclause in the query is then executed. -
Each ACTED_IN relationship to the same Hip Hop Witch, Da movie is traversed to retrieve all actors.
Notice that for this query, a depth-first traversal occurs just as it did for the previous query.
The one difference in the outcome, however is that the Eminem node is added as a result of the second MATCH.
Avoiding labels for better performance
Another graph optimization that you can take advantage of is to reduce labels used in your query patterns. Having a label for the anchor nodes in a pattern is good:
PROFILE MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = 'Tom Hanks'
RETURN m.title AS movieThe Person label for the anchor node retrieval is good here, but the label for the other side of the pattern is unnecessary. Having the label on the non-anchor node forces a label check, which is really not necessary.
Here is a more performant way to do this query:
PROFILE MATCH (p:Person)-[:ACTED_IN]->(m)
WHERE p.name = 'Tom Hanks'
RETURN m.title AS movieWith this second query, you see that there are fewer db hits.
Returning paths
In Neo4j Browser, when you return nodes, by default the relationships are visualized. For example, this query is visualized with its associated paths that were traversed for the query:
MATCH (person:Person)-[]->(movie)
WHERE person.name = 'Walt Disney'
RETURN person, movieThe visualization includes one Person node that is connected to four Movie nodes using five relationships. The objects that are returned (table view), are five rows where the Person node values are in each row and the one Movie node is repeated. There is no relationship information returned.
You can return paths in your query as follows:
MATCH p = ((person:Person)-[]->(movie))
WHERE person.name = 'Walt Disney'
RETURN pThis query returns 5 paths. If you view the objects (table view in Neo4j Browser), you will see that each row returned represents the Person node, the Movie node, and the relationship.
In some applications, it may be useful to work with path objects. Cypher has some useful functions that can be used to analyze paths:
-
length(p)returns the length of a path. -
nodes(p)returns a list containing the nodes for a path. -
relationships(p)returns a list containing the relationships for a path.
Check your understanding
1. Best query performance
We want to return a list of names of reviewers who rated the movie, Toy Story. What query will perform best?
Once you have selected your option, click the Check Results query button to continue.
/*select:MATCH (movie:Movie)<-[:RATED]-(reviewer:User)*/
WHERE movie.title = 'Toy Story'
RETURN reviewer.name-
✓
MATCH (movie:Movie)←[:RATED]-(reviewer) -
❏
MATCH (movie:Movie)←[:RATED]-(reviewer:User) -
❏
MATCH (movie)←(reviewer:User) -
❏
MATCH (movie)←(reviewer)
Hint
Use specific relationships and labels for the anchor nodes only.
Solution
The correct answer is: MATCH (movie:Movie)←[:RATED]-(reviewer) will perform the best because it uses a label for the anchor node, Movie and specifies the relationship type.
You need not specify a label for non-anchor nodes in the pattern.
Specifying the relationship type in a pattern will always yield better performance.
2. Traversing the graph
What term best describes the traversal behavior during a query?
-
✓ depth-first
-
❏ breadth-first
Hint
The graph engine always traverses a complete path through the graph.
Solution
The correct answer is: depth-first
Summary
In this lesson, you learned how to graph traversal works and that how it can impact query performance.
In the next challenge, you will answer some questions about a graph traversal.