Introduction
At a high-level, GDS works by transforming and loading data into an in-memory format that is optimized for high-performance graph analytics. GDS provides graph algorithms, feature engineering, and machine learning methods to execute on this in-memory graph format. This enables the efficient and scalable application of data science to large graphs including representations of entire graph databases or large portions of them.
In this lesson we will cover the high-level workflow in GDS, as well as CPU and memory configuration to support that workflow.
General Workflow
Below is diagram illustrating the general workflow in GDS, which breaks out into 3 high-level steps
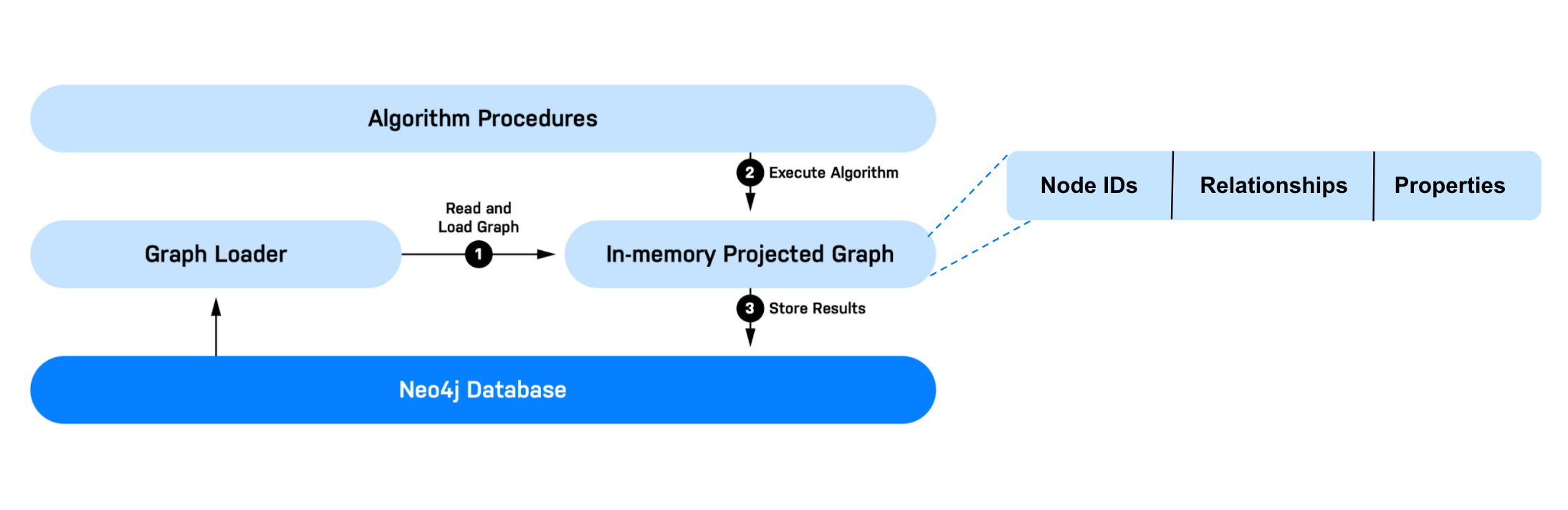
-
Read and Load the Graph: GDS needs to read data from the Neo4j database, transform it, and load it into an in-memory graph. In GDS we refer to this process as projecting a graph and refer to the in-memory graph as a graph projection. GDS can hold multiple graph projections at once and they are managed by a component called the Graph Catalog. We will go over the graph Catalog and graph projection management in more detail in the next module.
-
Execute Algorithms: This includes classic graph algorithms such as centrality, community detection, path finding, etc. It also includes embeddings, a form of robust graph feature engineering, as well as machine learning pipelines.
-
Store Results: There are a few things you may want to do with the output/result of graph algorithms. GDS enables you to write results back to the database, export to disk in csv format, or stream results into another application or downstream workflow.
GDS Configuration
GDS runs greedily in respect to system resources which means it will use as much memory and CPU cores as it needs - not exceeding limits configured by the user.
If you are running in AuraDS, the GDS configuration is fully managed out-the-box, so the below information won’t be relevant to getting started. For other Neo4j deployments, however, configuring workloads and memory allocation to make best use of the available system resources is important to maximize performance.
CPU and Concurrency
GDS uses multiple CPU cores for graph projections, algorithms, and writing results. This allows GDS to parallelize its computations and significantly speed up processing time. The level of parallelization is configured per execution via the concurrency parameter in the projection, algorithm, or other operation method.
The default concurrency used for most operations in GDS is 4. 4 is also the maximum concurrency that can be used with the Community license. In GDS Enterprise, concurrency is unlimited.
Memory
GDS runs within a Neo4j instance and is therefore subject to the general Neo4j memory configuration. Below is an illustration of Neo4j memory management. Neo4j uses the Java Virtual Machine (JVM) and, as such, memory management is divided into heap and off-heap usage.
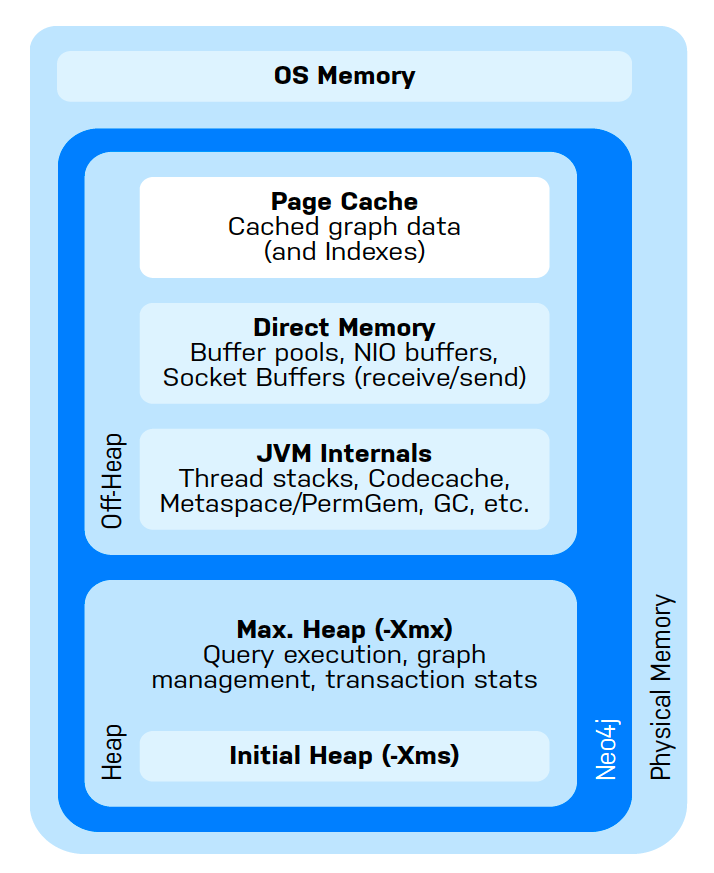
Of the above, two main types of memory can be allocated in configuration:
-
Heap Space: Used for storing in-memory graphs, executing GDS algorithms, query execution, and transaction state
-
Page Cache: Used for indexes and to cache the Neo4j data stored on disk. Improves performance for querying the database and projecting graphs.
Recommendations for Memory Configuration
Data Science computing has a tendency to be memory intensive and GDS is no exception. In general, we recommend being generous when configuring the heap size, allocating as much heap as possible while still providing sufficient page cache to load your data and support Cypher queries. This can be done via the dbms.memory.heap.initial_size and dbms.memory.heap.max_size in the Neo4j configuration.
You can also use Memory Estimation to gauge heap size requirements early on. Memory estimation is a procedure in GDS which allows you to estimate the memory needed for running a projection, algorithm, or other operation on your data BEFORE actually executing it. We will go through the exact commands for memory estimation in our Neo4j Graph Data Science Fundamentals Course.
As far as page cache is concerned, for purely analytical workloads it is recommended to decrease page cache in favor of an increased heap size. However, setting a minimum page cache size is still important when projecting graphs. This minimum can be estimated at approximately 8KB * 100 * readConcurrency for standard, native, projections. Page cache size can be set via dbms.memory.pagecache.size in the Neo4j configuration.
For more information and detailed guidance on tuning these configurations please see the systems requirements documentation.
Check your understanding
1. GDS Workflow
GDS transforms and loads data into:
-
❏ a graph OLAP cube
-
✓ an in-memory graph format
-
❏ a separate analytical view stored on disk with the database
-
❏ a Python process
Hint
Performing graph algorithms in-memory offers several benefits, including faster computation and analysis due to reduced I/O overhead, improved scalability and efficiency in handling large graph datasets, and the ability to iterate and explore graph structures dynamically without the need for persistent storage operations.
Solution
The answer is an in-memory graph format.
2. CPU Configuration
How is CPU concurrency configured in GDS?
-
✓ Per execution via the concurrency parameter in the projection, algorithm, or other operation method
-
❏ GDS runs within a Neo4j instance and is therefore subject to the general Neo4j concurrency setting in the Neo4j configuration
-
❏ GDS has its own properties file where the concurrency setting can be set
-
❏ Concurrency cannot be configured in GDS
Hint
To configure CPU concurrency in GDS (Graph Data Science), you can set the concurrency parameter in the projection, algorithm, or other operation method during execution.
Solution
The answer is Per execution via the concurrency parameter in the projection, algorithm, or other operation method.
3. Memory Configuration
If you want to increase memory allocation to handle the creation of larger graph projections in GDS, which configuration(s) would you increase?
-
❏ The graph projection is stored off-heap in transaction state, so you would increase
dbms.tx_state.off_heap.max_cacheable_block_size -
❏ The graph projection is stored off-heap in the database cache, so you would increase
dbms.memory.pagecache.size -
❏ The graph projection is stored on-heap, so you would increase
dbms.memory.heap.size -
✓ The graph projection is stored on-heap, so you would increase
dbms.memory.heap.initial_sizeand/ordbms.memory.heap.max_size
Hint
The graph projection is stored on-heap, the initial and maximum size of which can be configured to handle larger graph projections.
Solution
The graph projection is stored on-heap, so you would increase dbms.memory.heap.initial_size and/or dbms.memory.heap.max_size.
Summary
In this lesson you learned about how GDS works and the high-level workflow in GDS. You also learned about GDS concurrency and Neo4j memory configurations to support GDS workloads.
In the next module you will learn about graph management, the graph catalog, and working with graph projections in more detail.