Relationships in the graph
Neo4j as a native graph database is implemented to traverse relationships quickly. In some cases, it is more performant to query the graph based upon relationship types, rather than properties in the nodes.
Let’s look at a new use case:
Use case #12: What movies did an actor act in for a particular year?
We can execute this query with the current graph:
MATCH (p:Actor)-[:ACTED_IN]-(m:Movie)
WHERE p.name = 'Tom Hanks' AND
m.released STARTS WITH '1995'
RETURN m.title AS MovieIt returns the movie, Apollo 13:
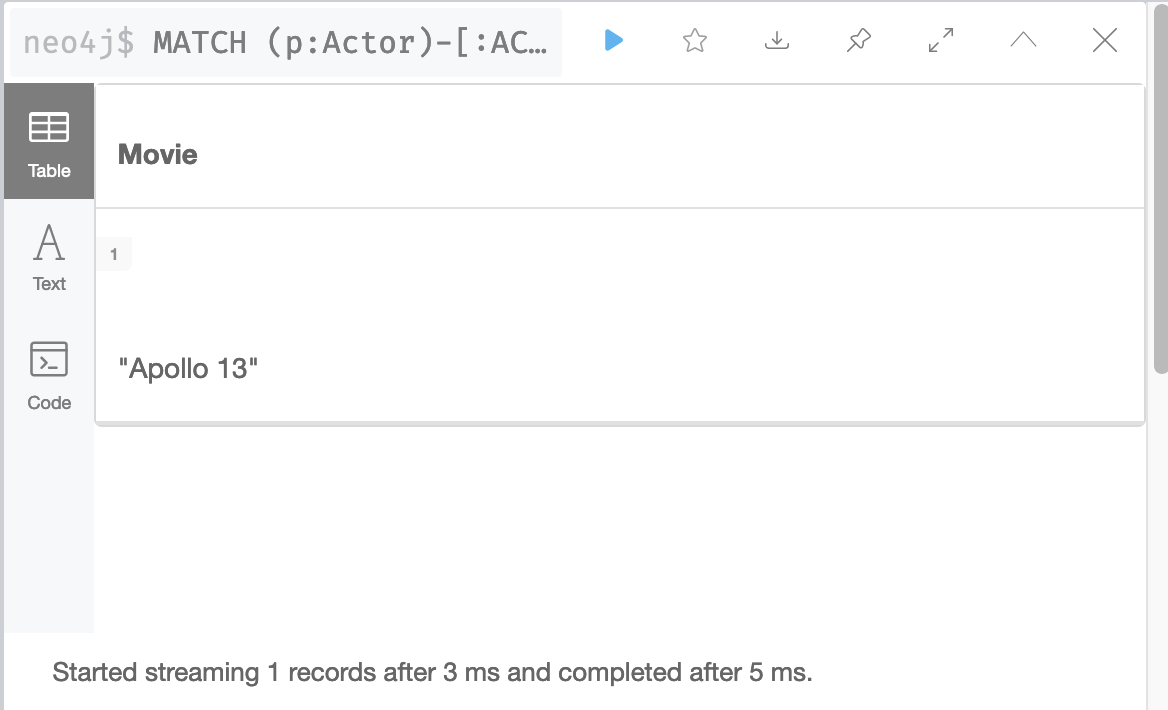
What if Tom Hanks acted in 50 movies in the year 1995? The query would need to retrieve all movies that Tom Hanks acted in and then check the value of the released property. What if Tom Hanks acted in a total of 1000 movies? All of these Movie nodes would need to be evaluated.
And here is another new use case:
Use case #13: What actors or directors worked in a particular year?
Again, we can execute this query with the current graph:
MATCH (p:Person)--(m:Movie)
WHERE m.released STARTS WITH '1995'
RETURN DISTINCT p.name as `Actor or Director`It returns Tom Hanks and Martin Scorsese:
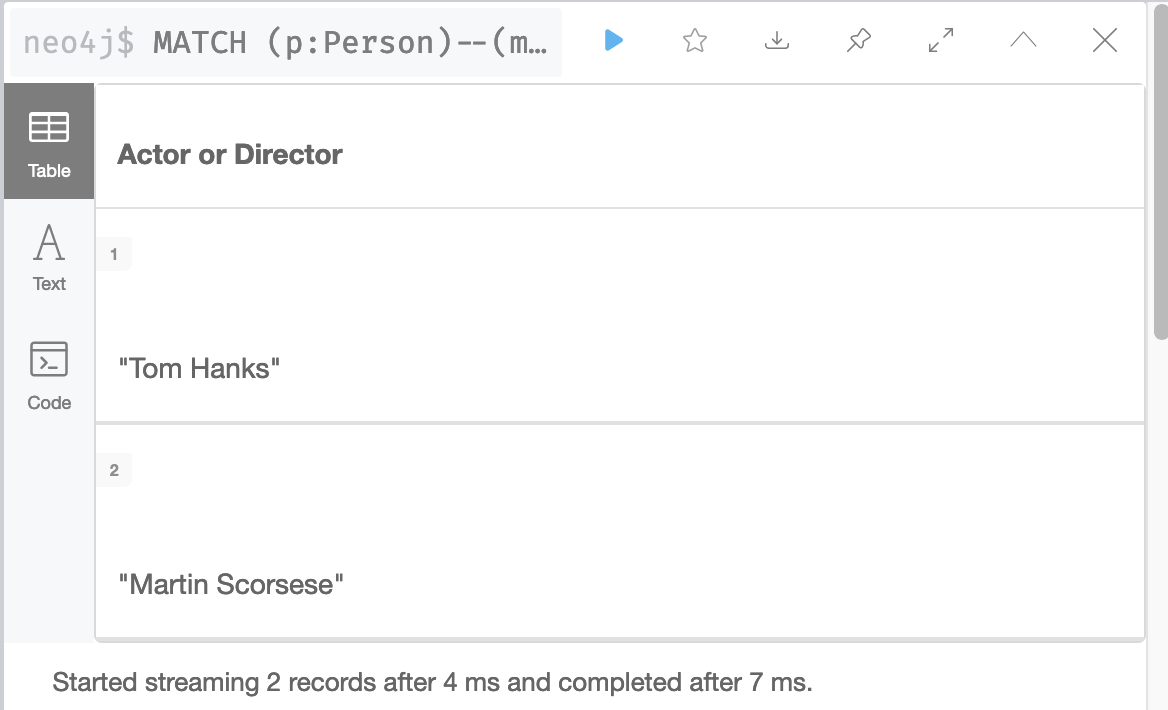
This query is even worse for performance because in order to return results, it must retrieve all Movie nodes. You can imagine, if the graph contained millions of movies, it would be a very expensive query.
Refactoring to specialize relationships
Relationships are fast to traverse and they do not take up a lot of space in the graph. In the previous two queries, the data model would benefit from having specialized relationships between the nodes.
So, for example, in addition to the ACTED_IN and DIRECTED relationships, we add relationships that have year information.
-
ACTED_IN_1992
-
ACTED_IN_1993
-
ACTED_IN_1995
-
DIRECTED_1992
-
DIRECTED_1995
At first, it seems like a lot of relationships for a large, scaled movie graph, but if the latest two new queries are important use cases, it is worth it.
This is what our instance model will now look like:
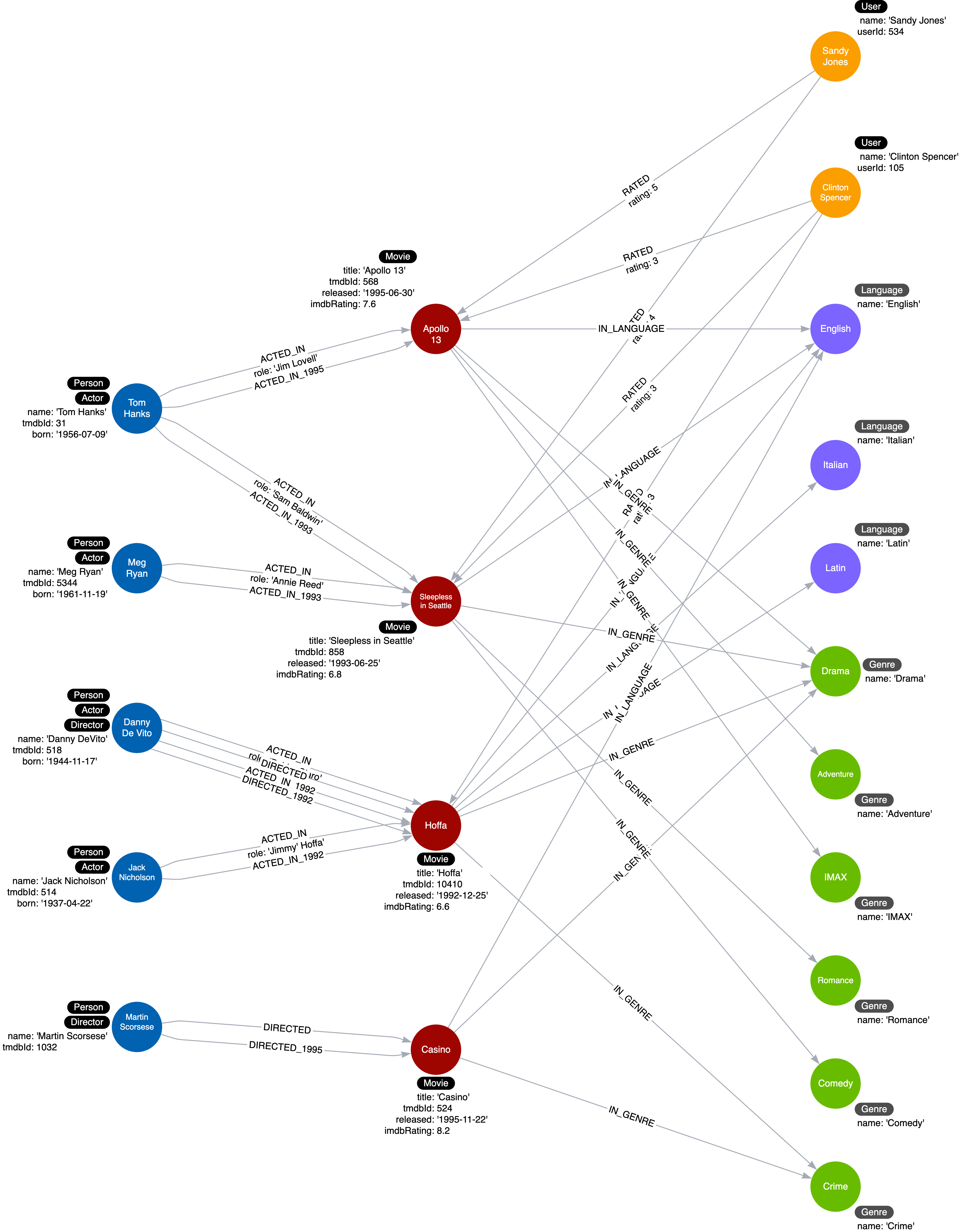
In most cases where we specialize relationships, we keep the original generic relationships as existing queries still need to use them.
The code to refactor the graph to add these specialized relationships uses the APOC library.
This is the code to refactor the ACTED_IN relationships in the graph that you will execute in the next Challenge:
MATCH (n:Actor)-[:ACTED_IN]->(m:Movie)
CALL apoc.merge.relationship(n,
'ACTED_IN_' + left(m.released,4),
{},
{},
m ,
{}
) YIELD rel
RETURN count(*) AS `Number of relationships merged`;It has a apoc.merge.relationship procedure that allows you to dynamically create relationships in the graph.
It uses the 4 leftmost characters of the released property for a Movie node to create the name of the relationship.
As a result of the refactoring, the previous two queries can be rewritten and will definitely perform better for a large graph:
Here is the rewrite of the first query:
MATCH (p:Actor)-[:ACTED_IN_1995]-(m:Movie)
WHERE p.name = 'Tom Hanks'
RETURN m.title AS MovieFor this query the specific relationship is traversed, but fewer Movie nodes are retrieved.
And here is how we rewrite the second query:
MATCH (p:Person)-[:ACTED_IN_1995|DIRECTED_1995]-()
RETURN p.name as `Actor or Director`For this query, because the year is in the relationship type, we do not have to retrieve any Movie nodes.
Check your understanding
1. Why specialize relationships?
Why do you refactor a graph to specialize relationships?
-
✓ Reduce the number of nodes that need to be retrieved.
-
✓ Improve query performance.
-
❏ Reduce storage required of the graph.
-
❏ Reduce the number of relationships in the graph.
Hint
Specialized relationships allow you to follow specific relationship types and avoid traversing a larger part of the graph in a single query.Both of these factors are a result of adding specialized relationships to the graph.
Solution
Specialized relationships allow you to follow specific relationship types and avoid traversing a larger part of the graph in a single query. This means that it will reduce the number of nodes that need to be retrieved and therefore improves query performance.
2. How do you create dynamic relationships?
What do you do to create a dynamic relationship in Cypher?
-
❏ Use Cypher conditional clauses to create the relationships.
-
❏ use the CREATE_RELATIONSHIP clause.
-
❏ Use the DBMS library.
-
✓ Use the APOC library.
Hint
This is a specialized procedure in a library available to the graph engine at runtime.
Solution
The APOC library contains a number of procedures that can be called to create labels and relationship types based on dynamic arguments passed to the procedure.
Summary
In this lesson, you learned why it may improve query performance if you specialize relationships in the graph. In the next challenge, you perform a refactoring that specializes the ACTED_IN and DIRECTED relationships in the graph.