Introduction
The goal of node embedding is to compute low-dimensional vector representations of nodes such that similarity between vectors (eg. dot product) approximates similarity between nodes in the original graph. These vectors, also called embeddings, can be extremely useful for exploratory data analysis, similarity measurements, and machine learning.
Intuition
The below figure illustrates the concept behind node embedding, whereby nodes that are close together in the graph end up being close together in the 2-dimensional embedding space. The embedding thus took the structure from the graph, the n-dimensional adjacency matrix, and approximated it in 2-dimensional vectors for each node. The embedding vectors are much more efficient to use for downstream process due to significantly reduced dimensionality. They could be used for cluster analysis for example, or as features to train a node classification or link prediction model.
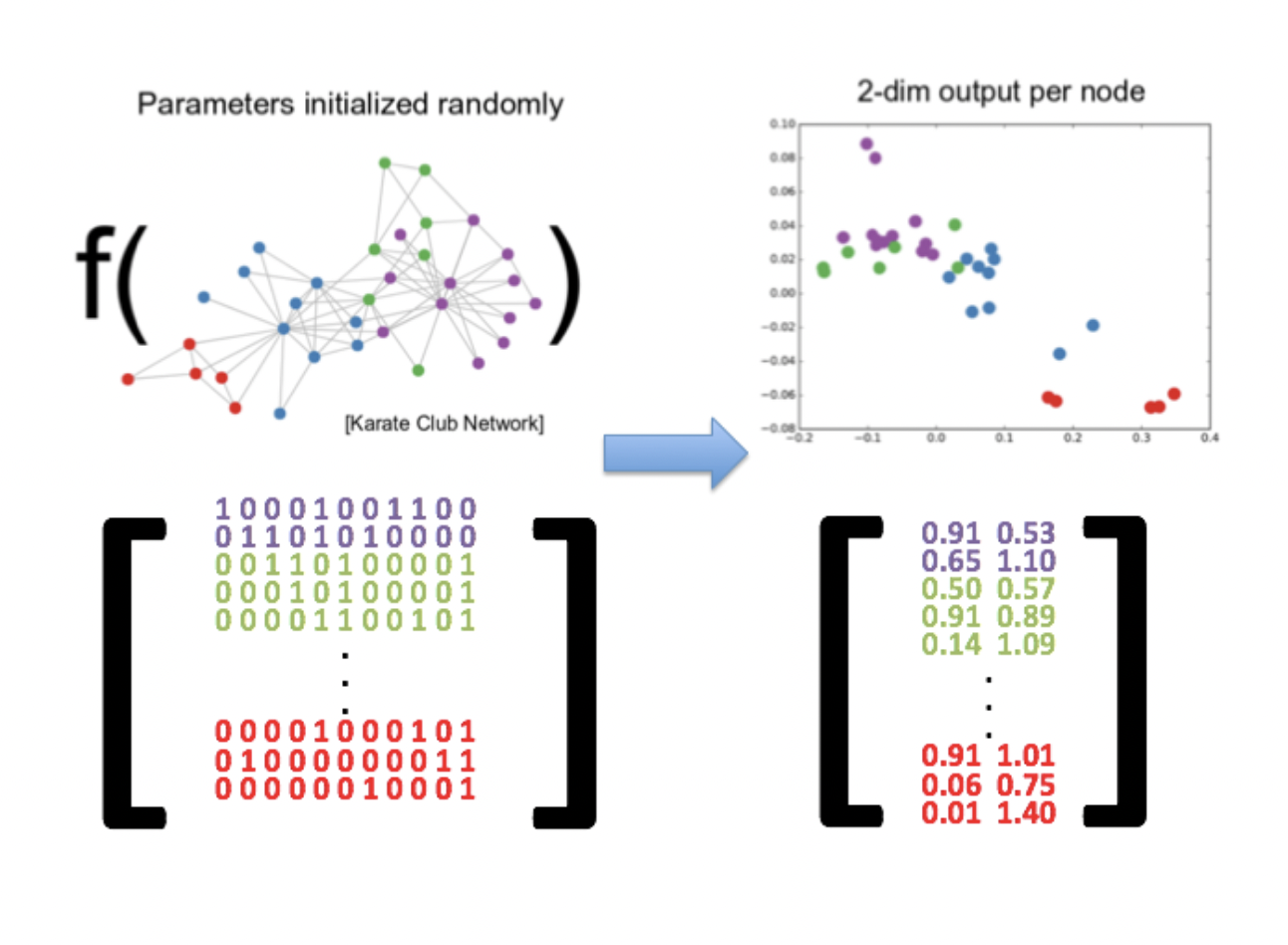
Of course, in real-world problems node embeddings will usually be larger than 2 dimensions, often ending up in the hundreds or larger, especially when applied to bigger graphs with millions or billions of nodes. Node embedding also doesn’t have to base similarity strictly on node proximity in the graph. While similarity based on distance in relationship hops and common neighbors is perhaps most common in application, node embedding can also consider node properties and other "global-view" node attributes when calculating embedding vectors.
Use Cases
Node embedding has applications across multiple use cases, from recommendations, to anomaly and fraud detection, entity resolution and other forms of knowledge graph completion.
Node embedding vectors don’t offer insights by themselves, they are created to enable or scale other analytics. Common workflows include:
-
Exploratory Data Analysis (EDA) such as visualizing the embeddings in a TSNE plot to better understand the graph structure and potential clusters of nodes
-
Similarity Measurements: Node embedding allows you to scale similarity inferences in large graphs using K Nearest Neighbor (KNN) or other techniques. This can be useful for scaling memory based recommendation systems, such as variations of collaborative filtering. It can also be used for semi-supervised techniques in areas like fraud detection, where, for example, we may want to generate leads that are similar to a group of known fraudulent entities.
-
Features for Machine Learning: Node embedding vectors naturally plug in as features for a variety of machine learning problems. For example, in a graph of user purchases for on online retailer, we could use embeddings to train a machine learning model to predict what products a user may be interested in buying next.
FastRP
GDS offers a custom implementation of a node embedding technique called Fast Random Projection, or FastRP for short. FastRP leverages probabilistic sampling techniques to generate sparse representations of the graph allowing for extremely fast calculation of embedding vectors that are comparative in quality to those produced with traditional random walk and neural net techniques such as Node2vec and GraphSage. This makes FastRP a great choice for getting started with exploring embedding on your graph in GDS.
There are multiple tuning parameters for FastRP and in real-world applications these can be important to take into account. A couple of considerable note below:
-
embeddingDimension: Applies to all node embedding algorithms in GDS. Controls the length of the embedding vectors. Setting this parameter is a trade-off between dimensionality reduction and accuracy. A larger embedding dimension will more accurately capture the graph structure but will also take longer to generate and produce embedding vectors that take more memory and computation to handle downstream. Choice of embedding dimension depends, in good part, on the number of nodes in the graph. Since the amount of information the embedding can encode is limited by its dimension, a larger graph will tend to require a larger embedding dimension. A typical value is a power of two in the range 128 - 1024. A value of at least 256 gives good results on graphs in the order of 100K nodes. -
IterationWeights: This controls two aspects: the number of iterations for intermediate embeddings, and their relative impact on the final node embedding. The parameter is a list of numbers, indicating one iteration per number where the number is the weight applied to that iteration. the default is[0.0, 1.0, 1.0]. In general, the intermediate embedding corresponding to thei:th iteration contains features depending on nodes reachable with paths of lengthi.
There are other parameters that control strength of normalization and node self-influence. As always, you can reference these in detail in the docs.
A last important note on FastRP is that, while we won’t cover it here, it has the ability to consider node and relationship property weights when generating embeddings. This can be useful for generating embedding vectors that encapsulate signal from both a weighted graph structure and other properties/attributes in the data. As always, you can reference the parameters and various configuration in more detail in the docs.
FastRP Example
Below is an example of generating FastRP embeddings on person nodes in the movies graph based on the movies they acted in and/or directed.
As always we will start with the graph projection
CALL gds.graph.project('proj', ['Movie', 'Person'], {
ACTED_IN:{orientation:'UNDIRECTED'},
DIRECTED:{orientation:'UNDIRECTED'}
});After that we will run FastRP. For demonstration purposes we will just use an embedding dimension of 64. We have the option of setting a randomSeed here as well to control consistency between runs.
CALL gds.fastRP.stream('proj', {embeddingDimension:64, randomSeed:7474})
YIELD nodeId, embedding
WITH gds.util.asNode(nodeId) AS n, embedding
WHERE n:Person
RETURN id(n), n.name, embedding LIMIT 10These embeddings, can, in theory, be used for similarity measurements to understand which actors are most similar and can be used in a content recommendation system to recommend movies to users based on the actors and/or directors for movies they recently viewed.
Check your understanding
1. Algorithm Purpose
What does node embedding accomplish (select all that apply)?
-
✓ Generates low-dimensional vector representations of nodes
-
❏ Embeds the graph into a single numeric vector to measure similarity to other graphs
-
✓ Provides numeric vectors that can be used for exploratory data analysis and similarity measurements between nodes
-
✓ Provides numeric vectors for each node that can be used as features for machine learning models
-
❏ Generates low-dimensional vector representations, each representing a path between node pairs
Hint
Node embeddings will not embed the graph into a single numerical vector or generate a low-dimensional vector representation of the graph.
Solution
The correct answers are:
Generates low-dimensional vector representations of nodes
Provides numeric vectors that can be used for exploratory data analysis and similarity measurements between nodes
Provides numeric vectors for each node that can be used as features for machine learning models
2. Algorithm Tuning
Which is a valid consideration for setting the embeddingDimension tuning parameter?
-
❏ The number of nodes in the graph. Generally larger graphs need larger embedding vectors to capture the graph structure
-
❏ Processing time and memory considerations. Smaller embeddings take less time to compute and have a smaller memory footprint
-
❏ The accuracy/completeness needed in downstream analytics that use the embeddings. Larger embeddings tend to estimate the graph structure more accurately
-
✓ All the above
Hint
You may consider all of the points mentioned above while setting the embeddingDimension tuning parameter.
Solution
The correct answer is All the above.
Summary
In this lesson you learned about Node Embeddings.
In the next module, you will learn more about Graph Machine Learning concepts.