Neo4j is a native graph database
Neo4j is a native graph database, meaning that everything from the storage of the data to the query language have been designed specifically with traversal in mind. Just like any other enterprise DBMS, Neo4j is ACID compliant. A group of modifications in a transaction will all either commit or fail.
Where native graph databases stand apart from other databases is the concept of index-free adjacency. When a database transaction is committed, a reference to the relationship is stored with the nodes at both the start and end of the relationship. As each node is aware of every incoming and outgoing relationship connected to it, the underlying graph engine will simply chase pointers in memory - something that computers are exceptionally good at.
Index-free adjacency (IFA)
One of the key features that makes Neo4j graph databases different from an RDBMS is that Neo4j implements index-free adjacency.
RDBMS query
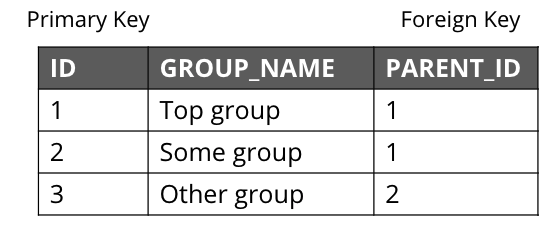
To better understand the benefit of index-free adjacency, let’s look at how a query executes in an RDBMS.
Suppose you have this table in the RDBMS.
You execute this SQL query to find the third-degree parents of the group with the ID of 3:
SELECT PARENT_ID
FROM GROUPS
WHERE ID = (SELECT PARENT_ID
FROM GROUPS
WHERE ID = (SELECT PARENT_ID
FROM GROUPS
WHERE ID = 3))The result of this query is 1, but in order to determine this result, the SQL Server needed to:
-
Locate the innermost clause.
-
Build the query plan for the subclause.
-
Execute the query plan for the subclause.
-
Locate the next innermost clause.
-
Repeat Steps 2-4.
Resulting in:
-
3 planning cycles
-
3 index lookups
-
3 DB reads
Neo4j storage
With index-free adjacency, Neo4j stores nodes and relationships as objects that are linked to each other via pointers. Conceptually, the graph looks like:

These nodes and relationships are stored as:

Neo4j Cypher statement
Suppose we had this query in Cypher:
MATCH (n) <-- (:Group) <-- (:Group) <-- (:Group {id: 3})
RETURN n.idUsing IFA, the Neo4j graph engine starts with the anchor of the query which is the Group node with the id of 3. Then it uses the links stored in the relationship and node objects to traverse the graph pattern.

To perform this query, the Neo4j graph engine needed to:
-
Plan the query based upon the anchor specified.
-
Use an index to retrieve the anchor node.
-
Follow pointers to retrieve the desired result node.
The benefits of IFA compared to relational DBMS access are:
-
Fewer index lookups.
-
No table scans.
-
Reduced duplication of data.
Check your understanding
Index-free adjacency
What are the three key benefits of Neo4j’s index-free adjacency?
-
❏ Foreign keys are built into each node.
-
✓ Fewer index lookups.
-
✓ No table scans.
-
✓ Reduced duplication of data.
Hint
In an RDBMS, you need foreign keys and tables to implement relationships whereas in Neo4j, you simply follow pointers to traverse relationships.
Solution
The three key benefits of Neo4j’s index-free adjacency are:
-
Fewer index lookups.
-
No table scans.
-
Reduced duplication of data.
Summary
In this lesson you learned how Neo4j’s implementation of index-free adjacency makes queries super fast. Next, you will learn how some non-graph data models can be represented as graphs.